Créer un dashboard en python avec Panel
Objectif : permalink
Centraliser et présenter sur une même page les divers indicateurs et informations de pilotage des bâtiments utilisés dans les études de réaménagement ou d'optimisation :
- la surface de plancher (sdp),
- la surface utile brute (sub),
- la surface utile net (sun),
- le ratio sun/sub qui permet de définir les bâtiments dit 'de bureau',
- le ratio sun / postes de travail (pdt) qui permet de déterminer l'optimisation des surfaces de bureau (le ratio cible de l'État est de 12m2 par poste de travail),
- le nombre d'amphithéâtres et de salles banalisées et leurs taux d'occupation N-1, qui permet d'apprécier l'utilisation effective des bâtiments d'enseignement.
- la répartition des surfaces au sein du bâtiment selon 3 critères : les typologies de pièces, les usages, et les occupants.
Les sources de données permalink
N'ayant pas d'accès au bases de données / API en direct pour les interroger depuis mon dashboard, j'ai réalisé 3 extractions depuis divers outils métier pour pouvoir exploiter la donnée avec pandas :
L'intégralité des pièces du patrimoine :
| Column | Non-Null Count | Dtype |
|---|---|---|
| NOM_SITE | 43487 | object |
| Bâtiment | 43487 | object |
| NOM_ETAGE | 43487 | object |
| LIBELLE_PIECE | 38090 | object |
| TYPE_PIECE | 43487 | object |
| NUMERO_INTERNE_PIECE | 43487 | int32 |
| USAGE_PIECE | 39921 | object |
| AFFECTATAIRE | 42008 | object |
| SDP | 43487 | float64 |
| SUB | 43487 | float64 |
| SUN | 43487 | float64 |
l'intégralité des réservations de salles pour l'année universitaire 2022-23 :
| Column | Non-Null Count | Dtype |
|---|---|---|
| Type Salle | 315009 | object |
| Année | 315009 | int64 |
| Libellé site | 315009 | object |
| Durée de l'activité | 315009 | float64 |
| Libellé de salle | 315009 | object |
| Libellé bâtiment | 315009 | object |
Les effectifs et postes de travail déclarés par bâtiment :
| Column | Non-Null Count | Dtype |
|---|---|---|
| numéro interne | 266 | int64 |
| bâtiments | 266 | object |
| Effectif déclaré | 266 | int64 |
| nb de poste de travail | 214 | float64 |
D'après la methode .nunique(), il y a dans notre patrimoine : 259 bâtiments, répartis sur 53 sites pour 1926 salles d'enseignement, dont il faut traiter les données pour les afficher sur notre dashboard.
Les libs python utilisés : permalink
- Pandas pour la manipulation de données,
- plotly-express pour les graphiques,
- Panel pour le dashboard interactif
Le code : permalink
import pandas as pd
import panel as pn
import plotly.express as px
df = pd.read_excel("Ensemble des pièces.xls")
adf =pd.read_csv('2022.csv', delimiter=';').groupby(['Salle SIPI'])['Durée de l\'activité'].sum().reset_index()
pdt = pd.read_excel("pdt.xls")
#un peu de nettoyage/ formatage
df = df.drop_duplicates(subset=['NUMERO_INTERNE_PIECE']) # on élimine les doublons de multi usage pour garder que le principal
df.rename(columns={'SDP - Surface de Plancher' : 'SDP', 'SUB - Surface Utile Brute' : 'SUB', 'SUN - Surface Utile Nette' : 'SUN'}, inplace=True)
df['SDP'] =df['SDP'].replace("," , ".", regex=True).astype(float)
df['SUB'] =df['SUB'].replace("," , ".", regex=True).astype(float)
df['SUN'] =df['SUN'].replace("," , ".", regex=True).astype(float)
df['NUMERO_INTERNE_PIECE']=df['NUMERO_INTERNE_PIECE'].astype(int)
adf['Salle SIPI'] =adf['Salle SIPI'].replace("ABY_" , "", regex=True).astype(int)
pdt.fillna(0, inplace=True)
df = df.set_index('NUMERO_INTERNE_PIECE').join(adf.set_index('Salle SIPI')).reset_index()
list_site = df['NOM_SITE'].sort_values().unique()
class building():
def __init__(self,bat):
#on recupère les données lié au bâtiment
self.name = bat
self.data = df[df['Bâtiment'] == bat]
self.sdp = round(self.data['SDP'].sum(),0)
self.sub = round(self.data['SUB'].sum(),0)
self.sun = round(self.data['SUN'].sum(),0)
self.sbCount =self.data[self.data['TYPE_PIECE' ] == "116-Salle banalisée"]['NUMERO_INTERNE_PIECE'].nunique()
self.amphiCount = self.data[self.data['TYPE_PIECE' ] == "117-Amphithéâtre"]['NUMERO_INTERNE_PIECE'].nunique()
self.pdtCount = pdt[pdt['Bâtiment'] == self.name]['Nombre de postes de travail'].values[0]
def chart(self, type): # une méthode pour créer les graphiques de répartition de surface
color_scale = px.colors.qualitative.Set2
#on définit les valeurs manquantes dans les types de pièces, affectataire et usage comme "Non déclaré"
self.data['TYPE_PIECE'] = self.data['TYPE_PIECE'].fillna( value="Non déclaré")
self.data['AFFECTATAIRE'] = self.data['AFFECTATAIRE'].fillna( value="Non déclaré")
self.data['USAGE_PIECE']= self.data['USAGE_PIECE'].fillna( value="Non déclaré")
if type =='typologie' :
sub_df = self.data.groupby(['TYPE_PIECE'])['SDP'].sum().reset_index()
name ='TYPE_PIECE'
if type =='affectataire' :
sub_df = self.data.groupby(['AFFECTATAIRE'])['SDP'].sum().reset_index()
name ='AFFECTATAIRE'
if type =='usage' :
sub_df = self.data.groupby(['USAGE_PIECE'])['SDP'].sum().reset_index()
name ='USAGE_PIECE'
pie_fig = px.pie(sub_df, values='SDP', names=name, color_discrete_sequence = color_scale)
pie_fig.update_traces(textposition='inside', direction ='clockwise', hole=0.3, textinfo="label+percent")
pie_fig.update_layout(uniformtext_minsize=10,
uniformtext_mode='hide',
title="Par "+type,
)
return pie_fig
def dataFrame(self,type) : # une méthode pour retourner un dataframe sortable des répartitions de surface
if type =='typologie' :
sub_df = self.data.groupby(['TYPE_PIECE'])['SDP'].sum().reset_index('TYPE_PIECE')
if type =='affectataire' :
sub_df = self.data.groupby(['AFFECTATAIRE'])['SDP'].sum().reset_index('AFFECTATAIRE')
if type =='usage' :
sub_df = self.data.groupby(['USAGE_PIECE'])['SDP'].sum().reset_index('USAGE_PIECE')
return pn.widgets.DataFrame(sub_df, sortable=True,row_height=25, widths={'index': 10, 'TYPE_PIECE':250, 'SDP': 50})
def tauxOccup(self): # une méthode pour retourner un dict des taux d'occupation des amphithéâtre et salles banalisées
t = df[df['Bâtiment'] == self.name]
tx = {
'amphi' : round(
100*(t[t['TYPE_PIECE' ] == "117-Amphithéâtre"]['Durée de l\'activité'].sum() / t[t['TYPE_PIECE' ] == "117-Amphithéâtre"]['NUMERO_INTERNE_PIECE'].nunique())/1120,
2),
'sb' : round(
100*(t[t['TYPE_PIECE' ] == "116-Salle banalisée"]['Durée de l\'activité'].sum() / t[t['TYPE_PIECE' ] == "116-Salle banalisée"]['NUMERO_INTERNE_PIECE'].nunique())/1120,
2)
}
return tx
def list_bat(site):
return list(df[df['NOM_SITE' ] == site]['Bâtiment'].sort_values().unique())
def siteName(site):
return pn.pane.Markdown(' # '+site)
def siteNbBat(site):
return df[df['NOM_SITE' ] == site]['Bâtiment'].nunique()
def siteSDP(site):
return round(df[df['NOM_SITE' ] == site]['SDP'].sum(),0)
def tab(bat):
b = building(bat)
type_chart = pn.widgets.Select(name='Selectionnez une valeur', options=['typologie','affectataire','usage'])
tabs = pn.Column(pn.pane.Markdown(' # '+b.name),
pn.pane.Markdown(' ## Surfaces légales'),
pn.Row(pn.indicators.Number(name='Surface de Plancher', value=b.sdp, format='{value} m2',font_size='28pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='Surface Utile Brute', value=b.sub, format='{value} m2',font_size='28pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='Surface Utile Nette', value=b.sun, format='{value} m2',font_size='28pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='Ratio SUN/SUB', value=round(100*(b.sun/b.sub),1), format='{value} %',font_size='32pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='Ratio SUN/PDT', value=round((b.sun/b.pdtCount),1), format='{value} m2',font_size='32pt',margin=25,styles={'text-align': 'center'}),
),
pn.Tabs(('Occupation',
pn.Column(
pn.pane.Markdown(" ## Taux d'occupation 2022-23"),
pn.Row(
pn.indicators.Number(name='Nombre d\'Amphi', value=b.amphiCount, format='{value}',font_size='28pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='tx occupation', value=b.tauxOccup()['amphi'], format='{value} %',font_size='28pt',margin=25,styles={'text-align': 'center' }),
pn.indicators.Number(name='Nombre de Salle banalisé', value=b.sbCount, format='{value}',font_size='28pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='tx occupation', value=b.tauxOccup()['sb'] , format='{value} %',font_size='28pt',margin=25,styles={'text-align': 'center'})
))),
('Répartion',pn.Column(
pn.pane.Markdown(' ## Répartition des Surfaces '),
pn.Row((type_chart)),
pn.Row(pn.bind(b.chart, type_chart), pn.bind(b.dataFrame, type_chart)),
)))
)
return tabs
def dash_builder():
select_site = pn.widgets.Select(name='Selectionnez un site', options=list(list_site))
select = pn.widgets.Select(name='Selectionnez un bâtiment', options=pn.bind(list_bat,select_site))
template = pn.template.FastListTemplate(
site= "DashPi",
title= "Dashboard immobilier",
sidebar=[pn.pane.Markdown(' # Un simple dashboard'),
pn.pane.Markdown("D'après des extractions Abyla et SAP BO"),
select_site,
select,
],
main =pn.Column(
pn.bind(siteName, select_site),
pn.Row(pn.indicators.Number(name="Nombre de bâtiment(s)", value=pn.bind(siteNbBat,select_site), format='{value}',font_size='32pt',margin=25,styles={'text-align': 'center'}),
pn.indicators.Number(name='Surface de Plancher Totale', value=pn.bind(siteSDP,select_site), format='{value} m2',font_size='32pt',margin=25,styles={'text-align': 'center'}),
),
pn.bind(tab, select)),
header_background ='#023047',
)
return template
app = dash_builder()
app.servable()Le résultat permalink
Une fois l'application lancé via la commande 'panel serve dash.py' on peut accéder au dashboard en local :
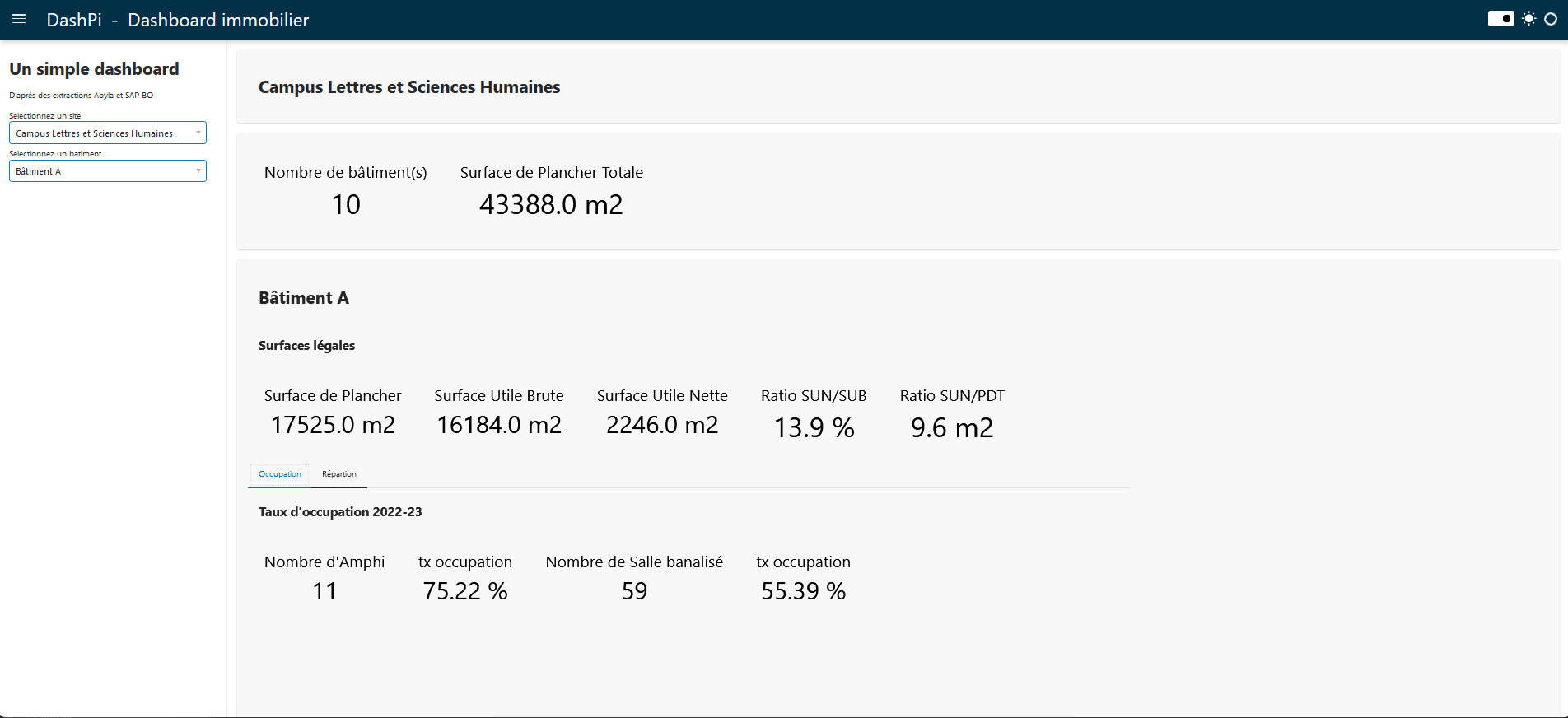
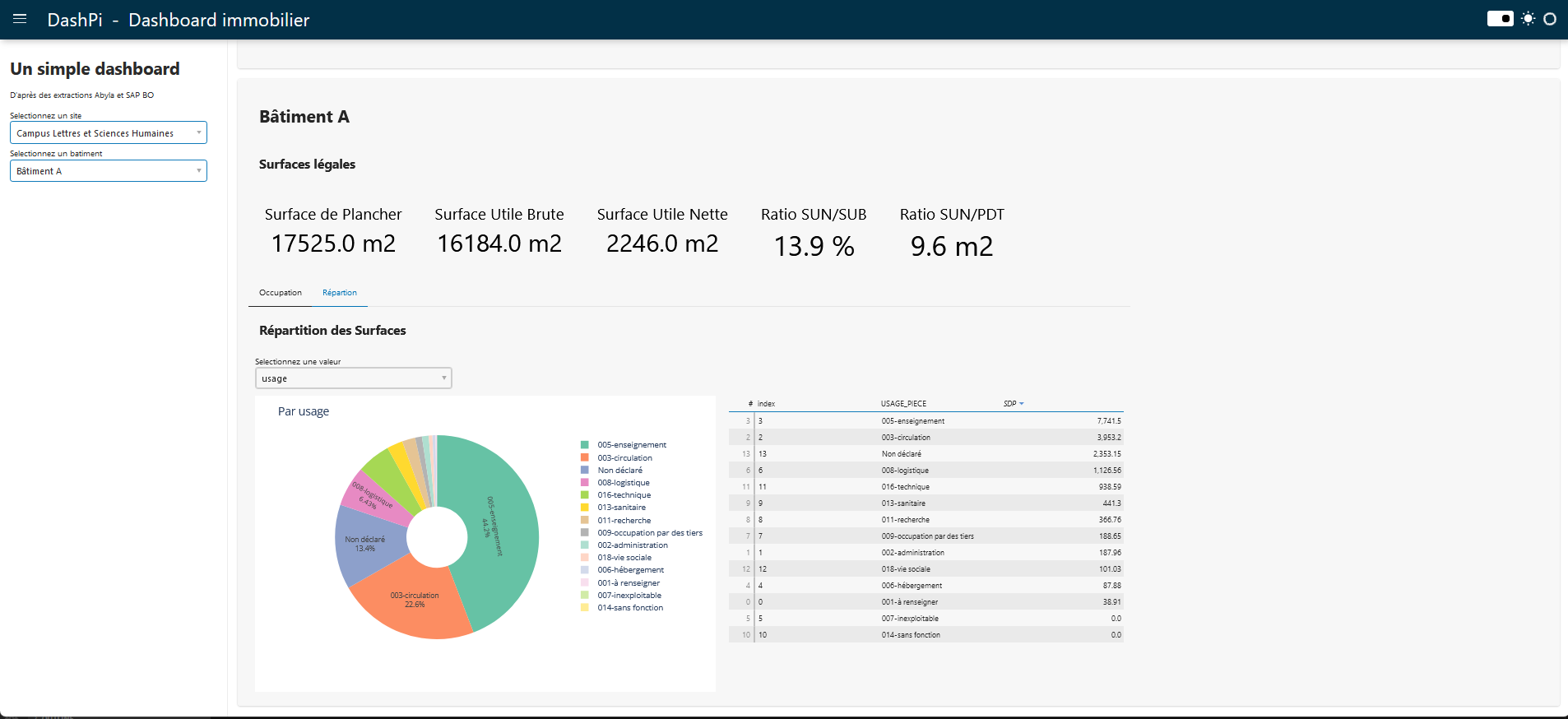
Pour l'instant, ce PoC n'a pas vocation à être mis en ligne ni même à être utilisé en interne, mais c'était un side projet très intéressant à mener pour découvrir la lib panel et produire un dashboard en utilisant autre chose que powerBI.